
Version 6.1
Clusters |
|---|
| ||||||||
|
|
Version 6.1 |
|||||||||||||||||||||||||||||||
|
|
The Storage Systems (such as disk devices) used today are "dumb" devices from the user and application point of view. Each system or a device has some number of blocks - fixed-size data segments, for example 1K (1024 bytes) in size. When the disk device is connected to a computer, it can process only very simple requests, such as:
Disks can be connected to computers using IDE, SCSI, or FDDI interfaces. These interfaces are used to send commands and data to the disks, and to retrieve the data and command completion codes from the disks.
Storage Systems themselves do not create any other structures, meaning that a disk device cannot create "files" or "file directories". The only thing these systems work with are blocks, and all they can do is read and write those blocks.
Every modern Operating System (OS) has a component called a File System. That component is part of the OS kernel and it implements things like "files" and "file directories".
There are many different File Systems, and they use various methods and algorithms, but the same basic functions are present in most File Systems: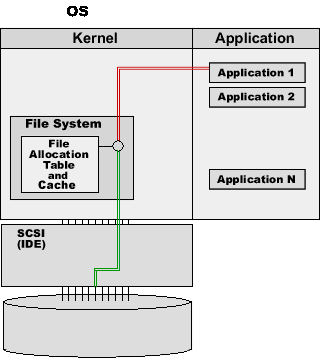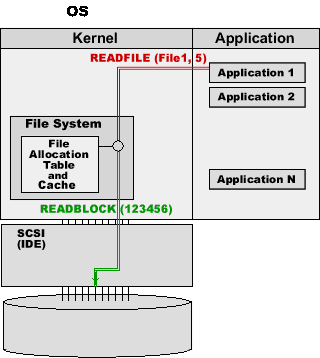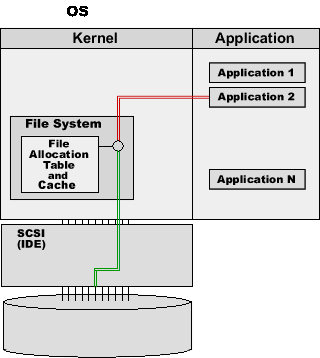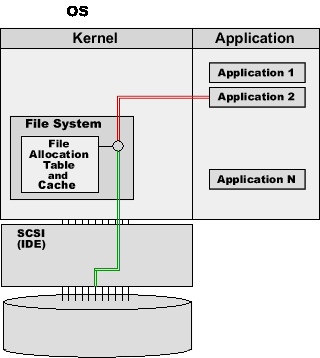
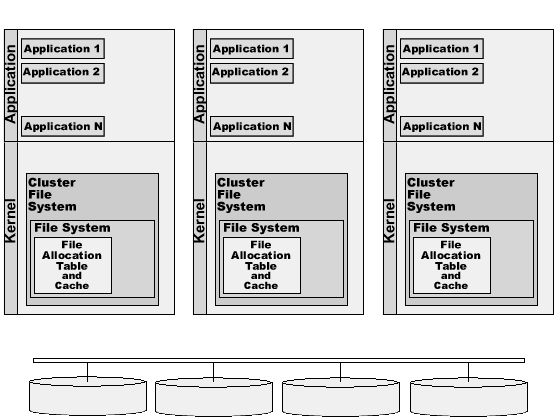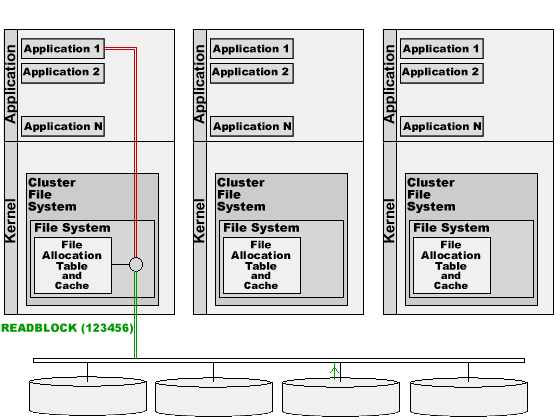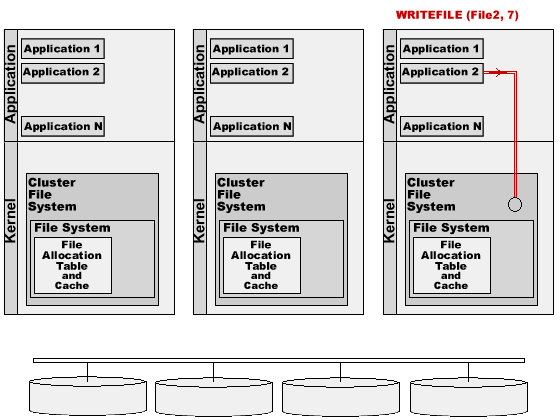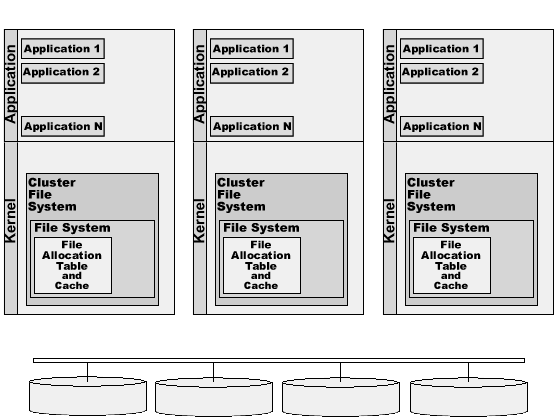
The File System uses the disk interface (IDE, SCSI, or any other one) to send the READBLOCK(123456) command to the disk.
The disk device sends the information from the specified block to the computer.
The File System places the read information into its cache buffers, and sends it to the application.
It removes the block number from the list of unused blocks and adds it as the 7th block to the File2 information in the File Allocation Table, so now File2 is 7 blocks in size.
The File System uses the disk interface (IDE, SCSI, or any other one) to send the WRITEBLOCK(13477) command to the disk, and sends the block data that the application program has composed.
The disk device writes the block data into the specified disk block, and confirms the operation.
The File System copies the block data information into its cache buffers.
If any application tries to read block 5 from File1 or block 7 from File2, the File System will retrieve the information from its cache buffers, and it will not perform any disk operation.
All applications running on this operating system use the same File System. The File System guarantees the data consistency. If the disk block 13477 is allocated to File2, it will not be allocated to any other file - until File2 is deleted or is decreased in size to less than 7 blocks.
When server computers need to use the same data, a Network File System (also called NAS, or Network Attached Storage) can be used.
The Network File System is implemented using a File Server and a network. The File Server is a regular computer or specialized OS that has a regular File System and regular disk devices controlled with this File System.
The Network File System "stubs" running inside the OS kernel on "client" computers are "dummy" File Systems that retranslate application file requests to the File Server, using the network:
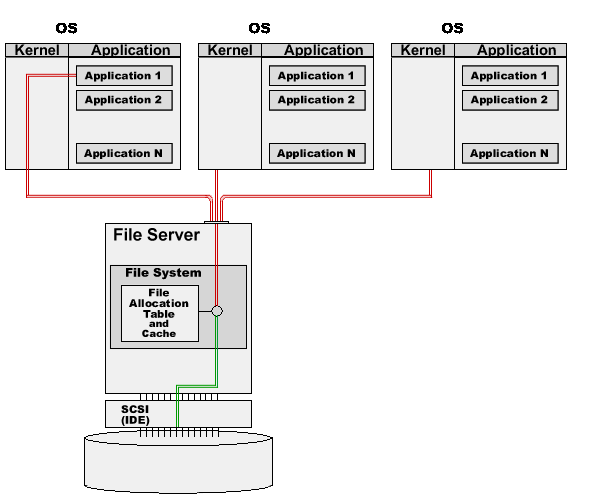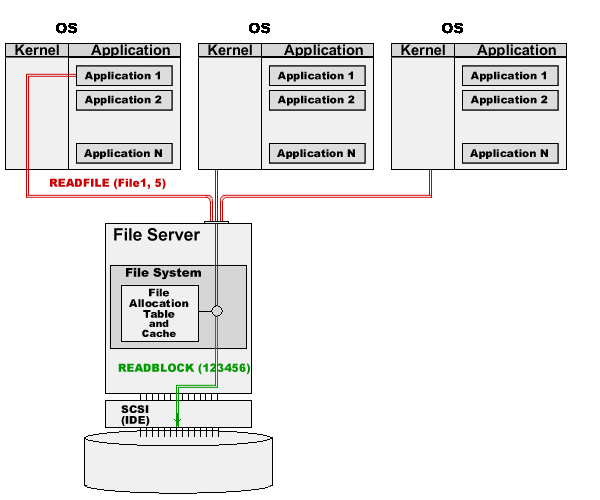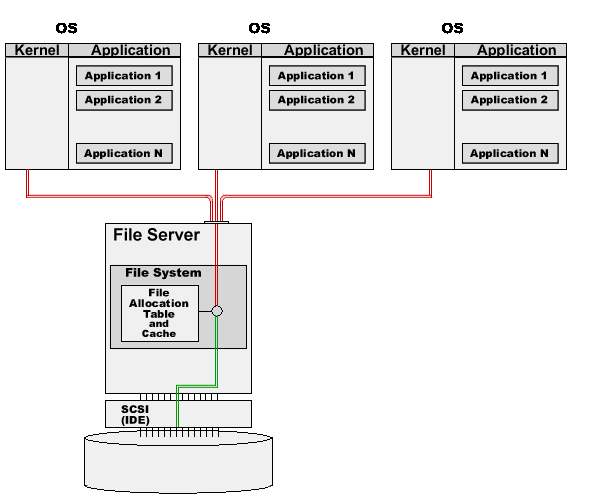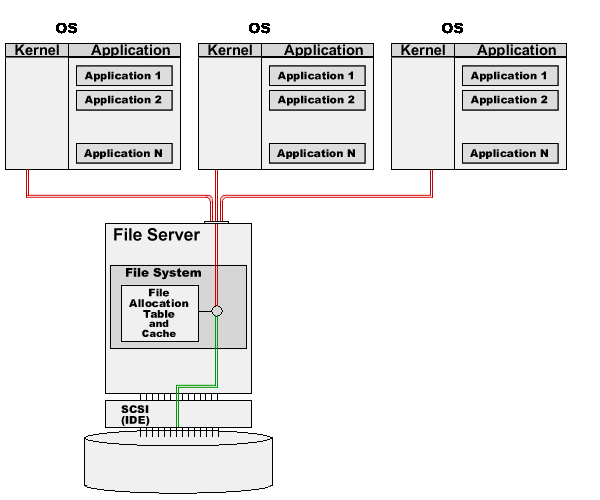
In this example, the File System on the File Server serves requests from several applications running on server "client" computers.
The only difference with the single OS is in the request delivery; instead of internal communication between an application and the File System running inside the OS kernel, the "stub" sends the requests via the network, receives the responses, and passes them to the application. All "real work" (File Allocation Table and cache maintenance) is done on the File Server computer.
Since only the File Server computer has direct access to the physical disk, all applications running on server systems use the same File System - the File System running on the File Server. That File System guarantees the data consistency. If the disk block 13477 is allocated to File2, it will not be allocated to any other file - until File2 is deleted or is decreased in size to less than 7 blocks.
Storage Area Network is a special type of network that connects computers and disk devices; in the same way as SCSI cables connect disk devices to one computer.
Any computer connected to SAN can send disk commands to any disk device connected to the same SAN. On the physical level, SAN can be implemented using FDDI, Ethernet, or other types of networks.
Some disk drives or arrays have "dual-channel" SCSI controllers and can be connected to two computers using regular SCSI cables. Since both computers can send disk read/write commands to that shared disk, this configuration has the same functionality as a one-disk SAN.
SAN provides Shared Disks, but SAN itself does not provide a Shared File System. If you have several computers that have access to a Shared Disk (via SAN or dual-channel SCSI), and try to use that disk with a regular File System, the disk logical structure will be damaged very quickly.
There are two main problems with Shared Disks and regular File Systems:
The File System running on that computer will modify its File Allocation Table, but it will have no effect on the File Allocation Tables loaded on other computers. If an application running on some other computer Y needs to expand a file, the File System running on that computer may allocate the same block 13477 to that other file, since it has no idea that this block has been already allocated by computer X.
A program running on some other computer Y can modify the information in the block 5 of File1. Since the File System running on computer X is not aware of this fact, it will continue to use its cache providing computer X applications with data that is no longer valid.
These problems make it impossible to use Shared Disks with regular File Systems as Shared File Systems. They can be used for fail-over systems or in any other configuration where only one computer is actually using the disk at any given time. The File System on computer Y starts to process the Shared Disk only when computer X has been shutdown, or stopped using the Shared Disk.
Cluster File Systems are software products designed to solve the problems outlined above. They allow you to build multi-computer systems with Shared Disks, solving the inconsistency problems.
Cluster File Systems are usually implemented as "wrapper" around some regular File System. Cluster File Systems use some kind of inter-server network to talk to each other and to synchronize their activities. That inter-server "interconnect" can be implemented using regular Ethernet networks, using the same SAN that connects computers and disks, or using special fast, low-latency "cluster interconnect" devices.
In this example, the Cluster File System is installed on several computers and serves requests from applications running on these computers.
The Cluster File System passes the request to the regular File System. It finds the information for File2 in the File Allocation Table, and detects that this file has 6 blocks allocated. It checks the list of unused disk blocks, and finds unused block number 13477. It removes the block number from the list of unused blocks and adds it as the 7th block to the File2 information in the File Allocation Table, so now File2 is 7 blocks in size.
The Cluster File System uses the inter-server network to notify the Cluster File Systems on other computers about the File Allocation Table modification. The Cluster File Systems on those computers update their File Allocation Tables to keep them in sync.
The File System uses the disk interface to send the WRITEBLOCK(13477) command to the Shared Disk, and sends the block data that the application program has composed.
The disk device writes the block data into the specified disk block, and confirms the operation.
The Cluster File System solves the inconsistency problems and allows several computers to use Shared Disk(s) as Shared File System.
Cluster File System products are available for several Operating Systems:
| Cluster File System | Operating System |
|---|---|
| Tru64 Cluster 5.x | HP Tru64 |
| VERITAS Cluster File System | Sun Solaris, HP/UX |
| Sun Cluster 3.0 | Sun Solaris |
| Generalized Parallel File System (GPFS) | IBM AIX, Linux |
| DataPlow | Linux, Solaris, Windows, IRIX |
| PolyServe | Linux |
| GFS | Linux |
| NonStop Cluster | Unixware |